相关链接:


Abstract
运筹学被广泛部署用于解决具有复杂目标和约束的关键决策问题,影响着制造、物流、金融和医疗健康等领域的结果。尽管大语言模型在各个领域都显示出了良好的结果,但它们在工业相关运筹学问题中的实际应用仍面临重大挑战与机遇。
将大语言模型应用于运筹学的初步工业应用面临两个关键的部署挑战:1) 自我修正侧重于代码语法而非数学准确性,导致代价高昂的错误;2) 复杂的专家选择机制创建了不可预测的工作流程,降低了透明度并增加了维护成本,使其难以适用于对时间敏感的商业应用。
为了解决这些业务限制,我们引入了ORMind,这是一个启发式的框架,通过反事实推理来增强优化。我们的方法模拟人类的认知——实现一个端到端工作流,系统地将需求转换为数学模型和可执行的求解器代码。
实验表明,ORMind优于现有的方法,在NL4Opt数据集上实现了9.5%的提高,在ComplexOR数据集上实现了14.6%的提高。
1. Introduction
由于业务需求和数学公式之间的脱节,优化项目面临30-40%的失败率。随着LLM的能力提升,使解决这种问题成为可能,目前范式是利用大语言模型的能力和知识从现实问题中提取隐变量和约束,基于这些信息建立求解器。
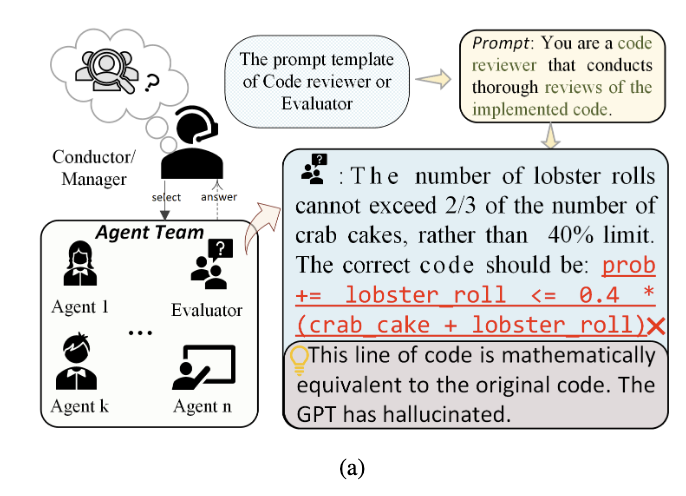
如图(a)所示,随着multi-agent逐渐复杂的编排以及复杂的api调用使得部署过程压垮了使用者,使得分析无从下手;并且agent推理是一个造成了大量开销的黑盒过程,与人类的推理过程有从根本上的不一致。
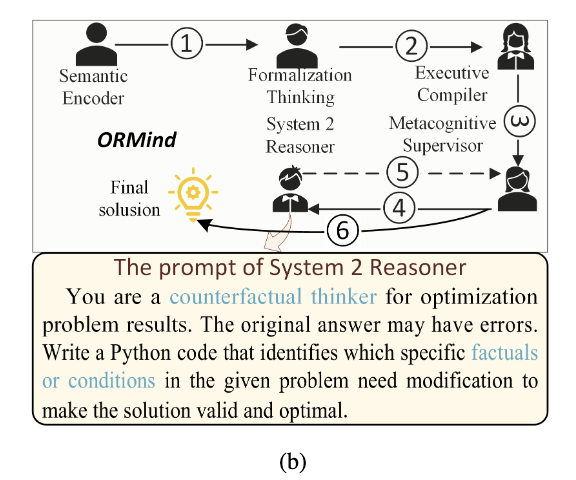
文中提到ORMind受到dual-process这个理论启发(联想思维与逻辑推理),即人脑思考有启发式过程与分析加工过程,将intuitive analysis数学分析过程与deliberate reasoning深度思考结合。ORMind先进行快速思考再到深入的数学思维,与之相对的,现有的multi-agent框架基于不可预测的agent选择agent与复杂编排,本文的框架创新于结构化、可观测的workflow,保持结果质量的同时减少api调用。
ORMind采用了简化的端到端工作流程和反事实推理,显著提高了解决方案的可靠性。
- 简化了工作流程
- counterfactual reasoning 反事实推理来验证约束的正确性
- 提高过程透明度
2. Related Work
2.1 基于LLM解决OR问题
需要一个系统来执行复杂的理解与推理,传统的方法将OR求解分解为两个独立的任务,首先求解NER任务以识别优化问题实体,然后生成优化公式的精确意义表示;另一条路则是使用LLMs来合成问题数据,用这些“合成出来的数据集”作为训练素材,对 LLM 进行微调(Fine-tuning)或训练,从而提升模型解决 OR 问题的能力,但是主要问题在于LLM合成数据可能存在质量问题、成本也更加高昂。
2.2 基于LLM的Multi-Agent工作流
通过多Agent协作的沟通的工作流比单LLM解决OR问题更有潜力,与现有工作项目,ORMind主要在反事实推理策略与multi-agent的记忆池沟通协作机制。
2.3 基于LLM的推理框架
目前随着LLM发展,涌现了各种创新的推理框架增强LLM复杂推理的能力。
但是single-agent在处理OR问题时出现了明显的短板,这种工作难以处理隐含约束与事实幻觉的知识密集的综合问题。
3. Methodology
3.1 Problem Formulation
minimize
subject to
3.2 Architecture Overview
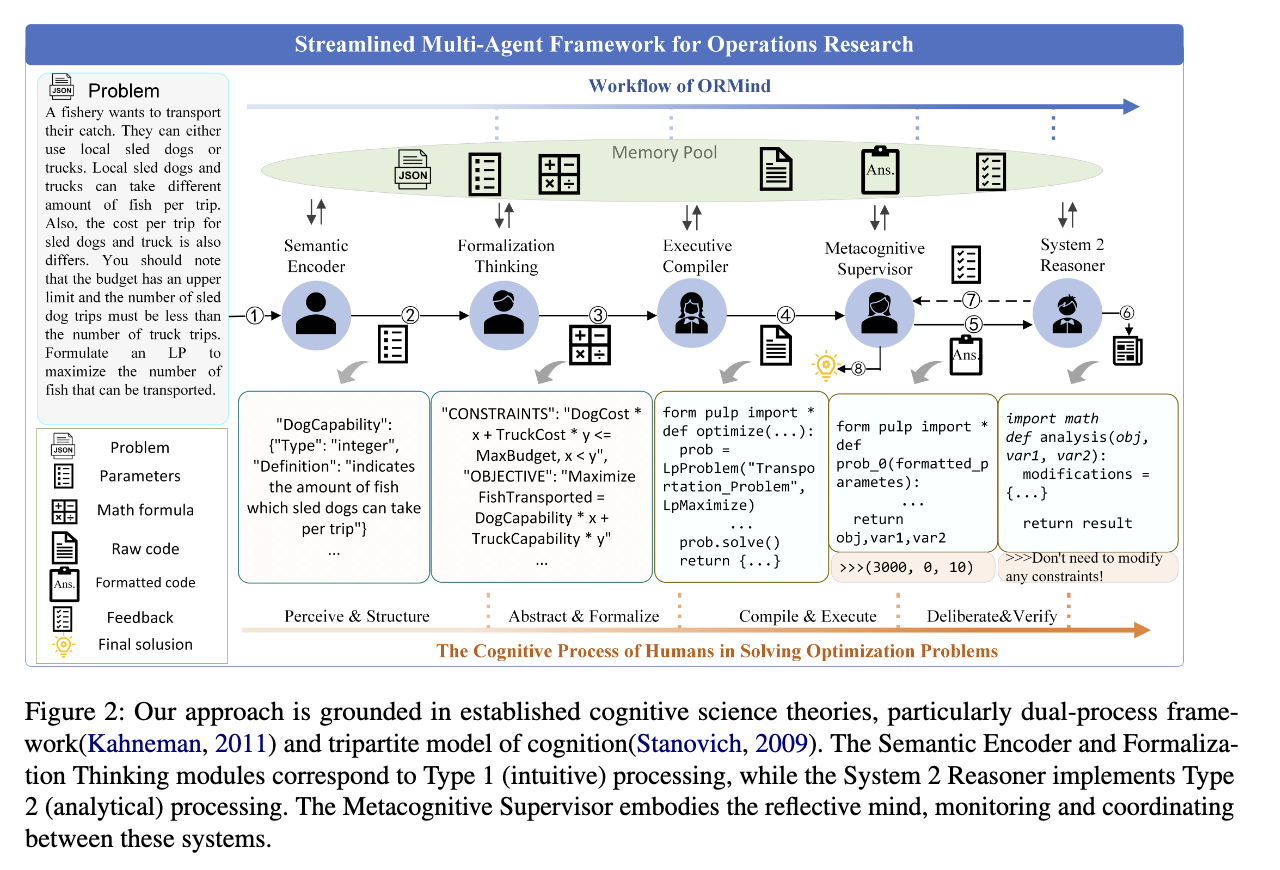
如图所示,整个系统结构是与人类思考过程相仿的。先在“大脑”中执行语义编码,从复杂的描述中快速识别关键变量;然后,它使用formalization thinking形式化思维,系统地采用数学表述变量和约束之间的关系;然后,执行编译器将这些抽象建模转换为可操作的解决方案。
给定问题输入和智能体序列,其中表示智能体总数,表示智能体特定的配置,每个组件基于存储在记忆池中的先前输出进行构建。
智能体的转换操作:
其中代表业务需求输入,包含所有先前处理过的输出。每个智能体的贡献逐步增强解决方案库:
这种协作式记忆架构通过利用专业化的专业知识,同时维护全面的解决方案上下文,解决了传统multi-agent方案不同agent间可能存在的上下文隔离的现象。

3.3 Brief Introduction of Components
3.3.1 Semantic Encoder
语义编码器将非结构化文本转换为结构化的知识表示,减少了工作记忆负荷。它将参数识别并分类为标量或向量,并确定每个参数的类型。输出是一个参数集 ,其中每个 代表一个参数及其关联信息。
3.3.2 Formalization Thinking
形式化思维执行深入的分析性思考以构建数学模型和约束条件。该智能体的关键步骤包括定义变量、制定约束和构建目标函数。这个组件模拟了人脑的抽象推理能力,领域专家通过概念抽象和关系映射在心理上将现实世界的情况转化为符号表示。
3.3.3 Executive Compiler
执行编译器将抽象模型转换为可执行的代码片段,类似于大脑执行功能的操作化过程。这种转换反映了实施计划的认知过程,人脑将抽象意图转化为具有精确操作细节的具体行动序列。
3.3.4 System 2 Reasoner
提供监督,同时通过反事实推理来测试解决方案,提出“如果……会怎样”的问题。传统方法通过直接检查约束条件来验证解,而ORMind会问“需要修改哪些约束才能使这个解决方案最优?”——本质上是从假设场景中学习以识别潜在缺陷。类似人类专家思考什么样的解决方案对最终答案会有什么样的影响,这种思考方式远比直接单独识别校验变量约束更加可靠。
这个组件还包括了传统模式中的语法校验,在由于语法错误导致代码执行失败的情况下,专家会找出问题行,并将可能的原因传达给Metacognitive Supervisor,以便快速解决。
ORMind的一个核心创新是使用反事实推理来识别错误和改进解决方案。假设优化问题可以用一个结构因果模型来描述,该模型包含变量、 和 ,其中:
其中 表示潜在变量。在ORMind中, 代表决策变量(例如,生产数量), 代表目标函数值(例如,总成本或利润), 封装了业务约束。
受认知科学中双过程理论的启发,ORMind将推理分为直觉(系统1)阶段和审慎、分析(系统2)阶段。
3.3.5 Metacognitive Supervisor
当检测到错误时,能够实现解决方案质量的自我意识、战略监督和自适应决策。它监控整个解决方案生成过程,进行高层次的决策调整
当在生产场景中检测到约束违反时:
其中 包含业务关键约束失败的详细信息。监督器利用这些信息来确定调整的优先级,以实现最大的修正。
一旦所有业务约束都得到满足:
这种可用于生产的状态 代表了一个经过部署验证的解决方案,满足所有业务需求和优化目标。
4. Enterprise Application
联想正在其AI助手系统中试点这种创新方法。该助手利用客户的计算需求和预算约束来建立数学模型,优化性能与成本之比。除了产品配置,联想的AI助手还在整个客户旅程中扩展了这种优化能力:它简化了售前产品推荐以缩短决策周期,在购买时自动应用最大折扣,并高效处理售后服务。
同时,ORMind正在进行内部评估,以增强涵盖292个产品类别、超过8,000个潜在SKU(由于业务规则要求库存且为直销产品,大约有2,000多个活跃SKU可供推荐)的产品配置。在测试期间,系统平均每天处理超过3,000个客户咨询,保持配置时间低于6秒,任务完成率超过80%。内部评估跟踪了其他指标:意图识别准确率达到85%以上,推荐采纳率(点击率)超过18%,平均客户满意度评分为4.2分(满分5分)。业务分析师发现系统的透明推理与他们自己的推理一致,能够实现快速验证和干预。
5. Experiments
5.1 Datasets
- NL4Opt
- ComplexOR
5.2 Experiment Setup and Metrics
GPT-3.5-turbo(主要使用)->GPT-4omini and GPT-4(鲁棒性测试)
- 成功率(SR):解决问题的成功率。
- 模型构建失败率(MFFR):由于约束解释错误导致系统未能构建有效数学模型的优化问题百分比。
- 实施执行失败率(IEFR):由于技术不兼容或资源限制导致求解器执行失败的优化模型百分比。
5.3 Baseline Comparison
以传统的方案作为对比,包括:Tag-BART (Gangwar, 2022)、Chain-of-Thought (Wei et al., 2022), Progressive Hint (Zheng et al., 2023), Tree-of-Thought (Yao et al., 2024), Graph-of-Thought (Besta et al., 2024), ReAct (Yao et al., 2023), Reflexion (Shinn et al., 2023), Solo Performance Prompting (Wang et al., 2024), CoE (Xiao et al., 2024) and OptiMUS (AhmadiTeshnizi et al., 2024)
5.4 Performance Evaluation
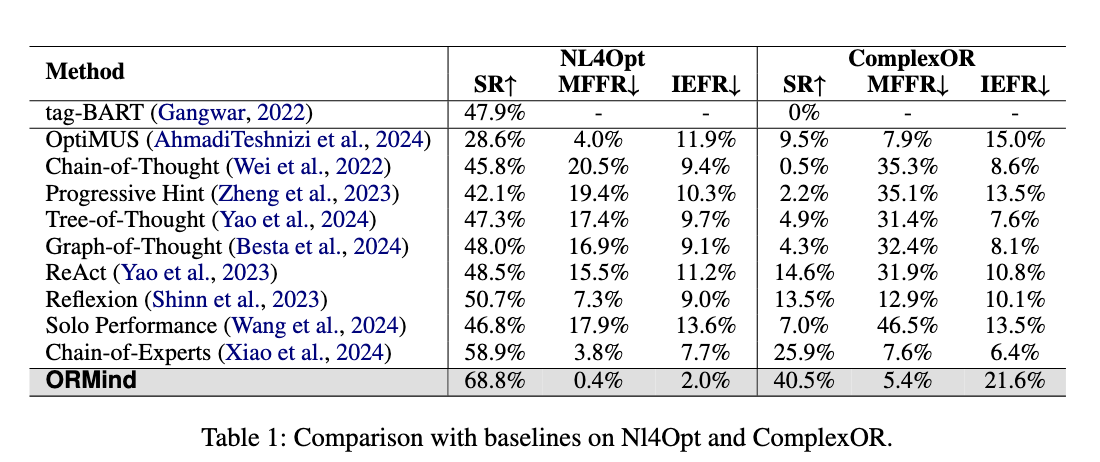
Tag-BART在ComplexOR的复杂场景中完全失败,而Reflexion显示出中等的错误处理能力。然而,在处理更复杂的ComplexOR问题时,ReAct的性能略微超过了Reflexion,这可能是由于其访问外部知识库的优势,突出了外部数据在处理复杂场景中的重要性。OptiMUS的结果引自其原始论文。当在GPT-3.5上进行测试时,由于其违反既定问题解决方法论的违反直觉的工作流程结构,其性能显著下降。在实践中,我们发现这些框架中调用智能体的顺序通常违反直觉,未能反映人类专家自然的问题解决过程。
NL4Opt和ComplexOR数据集之间的性能差异突出了一个关键发现:ORMind擅长准确地构建数学模型(在NL4Opt上实现接近零的MFFR),而在更复杂的工业场景中则面临实施挑战(在ComplexOR上有更高的IEFR)。这意味着ORMind在隐约束或者目标识别方面存在一定优势,但是在复杂的约束情况下,代码生成能力缺乏鲁棒性。
此前报告过OptiMUS这篇文章,在此附上原始论文的实验结果
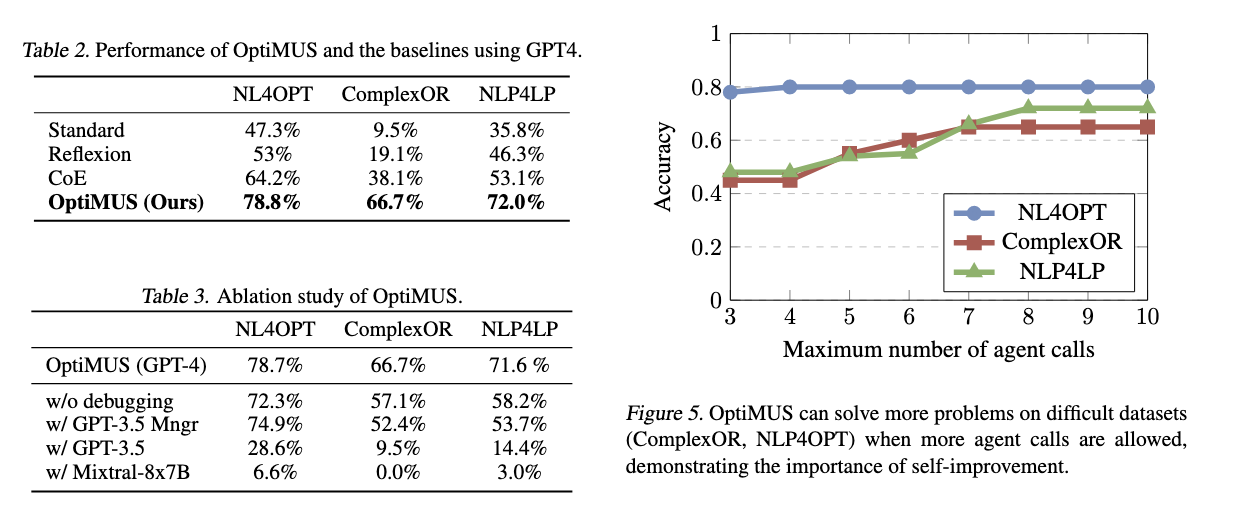
由于OptiMUS整体上下文以及multi-agent的交互开销较大,导致大部份组件无法更换为更便宜、规模更小的模型,一旦更换就会出现显著的性能下降,但是使用GPT-3.5来替换决策管理组件确实是可行的,决策并不需要长输出。
所以ORMind在减少cost开销这方面无疑是取得了一定成果的。
5.5 Ablation Study
5.5.1 Parameter Sensitivity Analysis
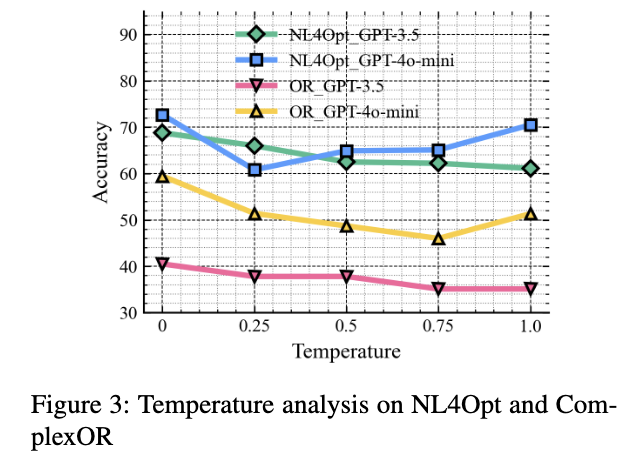
普遍地在低温情况下效果较好,意味着推理结果确实是更大可能为正确的。
5.5.2 Impact of Various Components.
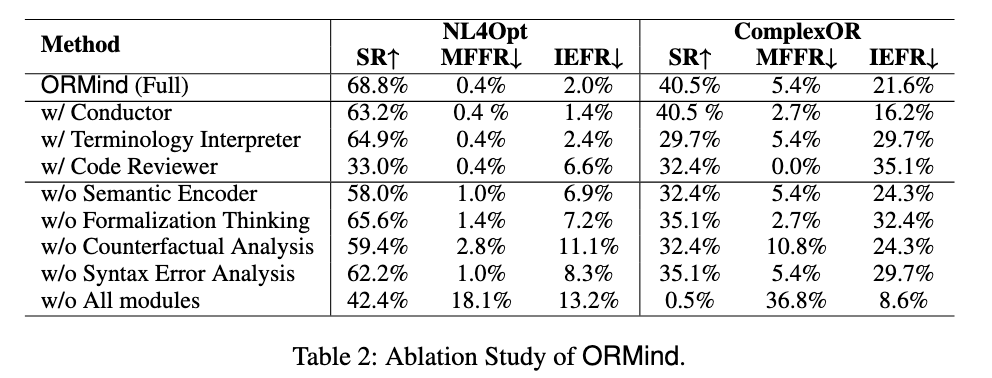
显然语义编码器与反事实推理这两个模块对于ORMind起着至关重要的作用,前者主要提高了准确率与降低约束识别错误率,而后者主要更全方位且更大幅度降低约束识别与代码执行错误率。引入额外组件都出现了准确率的下降,而Code Reviewer的引入更是极度反向优化;Conductor虽然降低了代码构造错误率,但是NL4Opt准确率出现了降低,并且增加了额外开销;而额外的术语解释器也是全方位的负优化。
5.5.3 Method Robustness
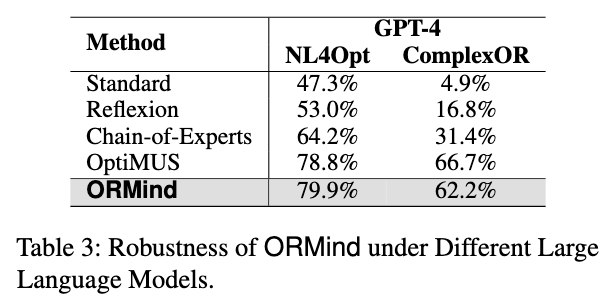
以GPT-4为基础模型的可靠性。各项指标上一致的性能提升证实了ORMind的架构有效地利用了先进的大语言模型,为业务运营提供了卓越的优化解决方案。
在NL4Opt的表现略为超越OptiMUS,但是实际复杂场景下的数据集表现不如OptiMUS,但是考虑到ORMind的开销小于OptiMUS(?)取得了相仿的结果
很大一个疑问是为什么它前面的实验不用GPT-4,跟其他论文统一一下指标。
5.5.4 Operational Efficiency
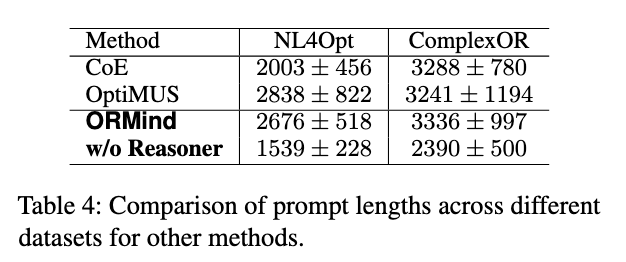
论文声称ORMind在企业级数据集上保持了最优的令牌效率,通过简化早期处理阶段减少了计算开销。消融研究表明,我们的系统在工业场景中展现出显著的鲁棒性、透明度和工程效率。
我是感觉有点扯淡了,整体框架肯定是需要Reasoner才能达到最优效果,但在这个条件下Prompt长度以及模型效果都贴近于OptiMUS,唯一值得称道的是ORMind在小一点规模的模型(GPT-3.5-turbo)表现要比OptiMUS好很多
6. Conclusion
略
Limitations
省流:依赖输入数据集的质量,在实际复杂场景及其表述中存在一定能力短板,更擅长纯粹的数学建模问题。
附录
附录G Agent-MemoryPool Interaction
Agent 主要对存储池进行检索与更新操作,执行任务前从记忆池检索相关信息:当前问题状态、先前识别的变量与约束、早期推理步骤的中间结果,增大了开销,但是确保了所有Agent都在使用最新的上下文。
当Agent完成任务后,就将结果更新到记忆池中。这些更新包括新发现的变量、约束、其他特定于任务的输出,以及总结推理过程的注释。每次更新都附带元数据标签,例如智能体标识符和时间戳,以保持可追溯性并便于调试。
随着新信息的出现,后续智能体可以重新审视和改进早期的结果,从而实现模块化和自适应的问题解决。这种集中式结构确保了系统的集体进展反映在单个共享存储库中,实现了所有智能体之间高效且一致的推理。
附录H 与现有方法比较
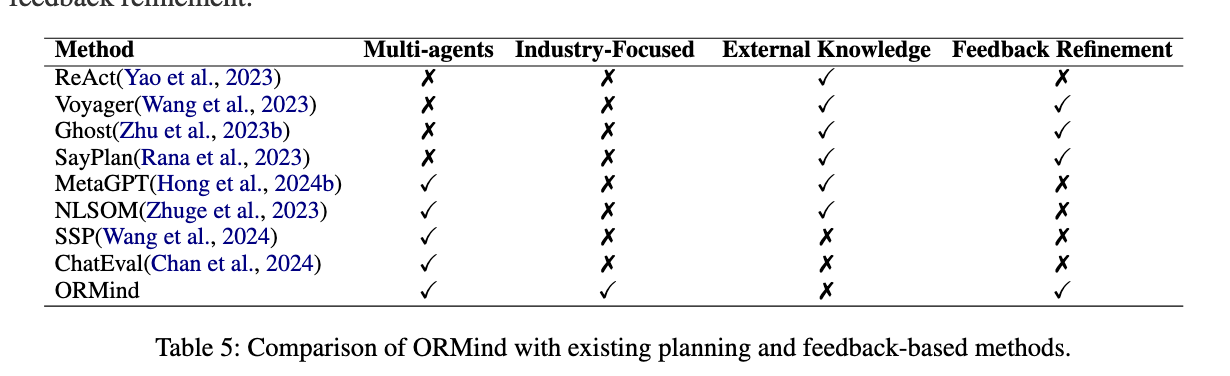
ORMind并未引入外部知识,更多的依赖模型自身的能力。
对比
OptiMUS 采用的 Gurobi,本文则采用的PuLP,结果导向来看使用不同求解器两者的最终得分是相近的,是否应该增加Prompt中指定采用不同求解器的得分对比。